- Регистрация
- 04.03.2011
- Сообщения
- 4 450
- Благодарностей
- 1 880
- Баллы
- 113
Вступление
В этой статье я хочу рассказать о регулярных выражениях. Для непосвященного пользователя они сложны для понимания, поэтому постараюсь максимально просто, с примерами, показать для чего и как они используются в Zennoposter. Надеюсь, данная статья будет полезна для всех!
Регулярные выражения достаточно широко используются в программе, а именно:
- Для поиска элементов;
- Во время парсинга данных с веб-сайтов или из файла;
- Для удобства обработки данных из различных источников (замене или удалению фрагментов текста);
- При установке разделителей в списках и таблицах;
- Многое другое.
Регулярное выражение - это язык поиска подстрок в тексте, основанный на использовании специальных символов и указателей. По сути это строка-образец, которая состоит из символов (статического текста) и спецсимволов (символов, обозначающих какие-то последовательности) и задаёт правило поиска подстроки в обрабатываемом тексте.
Для постройки регулярных выражений в программе есть специальный инструмент – «Конструктор регулярных выражений». В нём можно протестировать готовые выражения, а так же составить свои.

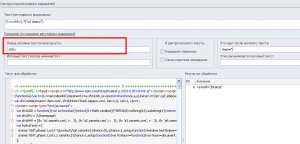
Возьмём текст и составим на его примере регулярное выражение так, чтобы получить домены сайтов:
В Конструкторе есть раздельные поля - текст, который идет перед искомым (<a href="), с которого начинается (http://), заканчивается искомый текст (.com), что идёт после него (">). В результате мы получим следующее регулярное выражение:
(?<=<a\ href=")http:.*?\.com(?=">) и список доменов в результатах тестирования.

Так же в Конструкторе имеется два чекбокса:
1) Разрешить переносы - включает и выключает поиск по тексту с учетом переносов строк (при включении данной опции, регулярное выражение не ограничено поиском в пределах одной строки, а так же учитывает переносы строк);
2) Самое короткое совпадение - включает и выключает поиск самого короткого совпадения. При включении данной опции, в результатах мы получим самую короткую подстроку, соответствующую составленному выражению. При выключении, соответственно - самую длинную.
При заполнении этих полей, Ваш текст автоматически преобразуется и в поле "Текст регулярного выражения" будет предоставлено готовое выражение, которое можно использовать для поиска.
Конструктор регулярных выражений, который есть в программе Zennoposter, достаточно не плох, но не универсален. Он подходит для составления простых выражений, когда мы имеем точные совпадения в тексте - что идет перед или после текста, который нам нужно найти, чем он начинается или чем заканчивается.Иногда, полученный результат бывает не удовлетворительным - строк больше или меньше, чем нужно, или просто вместо искомого текста мы получаем разный мусор. В таких случаях необходимы более широкие знания и правка выражений, сформированных Конструктором, вручную.
Для того, чтобы правильно самостоятельно составить регулярные выражения, рассмотрим основные символы, определим в какой ситуации они могут использоваться.
В этой статье я хочу рассказать о регулярных выражениях. Для непосвященного пользователя они сложны для понимания, поэтому постараюсь максимально просто, с примерами, показать для чего и как они используются в Zennoposter. Надеюсь, данная статья будет полезна для всех!
Регулярные выражения достаточно широко используются в программе, а именно:
- Для поиска элементов;
- Во время парсинга данных с веб-сайтов или из файла;
- Для удобства обработки данных из различных источников (замене или удалению фрагментов текста);
- При установке разделителей в списках и таблицах;
- Многое другое.
Регулярное выражение - это язык поиска подстрок в тексте, основанный на использовании специальных символов и указателей. По сути это строка-образец, которая состоит из символов (статического текста) и спецсимволов (символов, обозначающих какие-то последовательности) и задаёт правило поиска подстроки в обрабатываемом тексте.
Для постройки регулярных выражений в программе есть специальный инструмент – «Конструктор регулярных выражений». В нём можно протестировать готовые выражения, а так же составить свои.
Возьмём текст и составим на его примере регулярное выражение так, чтобы получить домены сайтов:
В Конструкторе есть раздельные поля - текст, который идет перед искомым (<a href="), с которого начинается (http://), заканчивается искомый текст (.com), что идёт после него (">). В результате мы получим следующее регулярное выражение:
(?<=<a\ href=")http:.*?\.com(?=">) и список доменов в результатах тестирования.
Так же в Конструкторе имеется два чекбокса:
1) Разрешить переносы - включает и выключает поиск по тексту с учетом переносов строк (при включении данной опции, регулярное выражение не ограничено поиском в пределах одной строки, а так же учитывает переносы строк);
2) Самое короткое совпадение - включает и выключает поиск самого короткого совпадения. При включении данной опции, в результатах мы получим самую короткую подстроку, соответствующую составленному выражению. При выключении, соответственно - самую длинную.
При заполнении этих полей, Ваш текст автоматически преобразуется и в поле "Текст регулярного выражения" будет предоставлено готовое выражение, которое можно использовать для поиска.
Конструктор регулярных выражений, который есть в программе Zennoposter, достаточно не плох, но не универсален. Он подходит для составления простых выражений, когда мы имеем точные совпадения в тексте - что идет перед или после текста, который нам нужно найти, чем он начинается или чем заканчивается.Иногда, полученный результат бывает не удовлетворительным - строк больше или меньше, чем нужно, или просто вместо искомого текста мы получаем разный мусор. В таких случаях необходимы более широкие знания и правка выражений, сформированных Конструктором, вручную.
Для того, чтобы правильно самостоятельно составить регулярные выражения, рассмотрим основные символы, определим в какой ситуации они могут использоваться.
- Тема статьи
- Другое
- Номер конкурса статей
- Четвертый конкурс статей
Для запуска проектов требуется программа ZennoPoster или ZennoDroid.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте нужную программу. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.









 :-)")