



Почему у меня медленно обрабатываются таблицы даже в многопотоке?
Задача - взять в одной таблице все значения, сравнить пару переменных, поменять пару значений и записать всё получившееся в другую таблицу.
Выполняется почему-то очень медленно.
Пробовал и xlsx и csv на вход и на выход, всё-равно медленно.
В таблице около 15тыс строк. Таблица до столбца AG это 34 столбца получается.
Неужели так сложно зенке взять строку со всех столбцов и записать её в другой файл, что так долго делает?
Обрабатывает это всё около часа на 20 потоках. Может я что делаю не так?
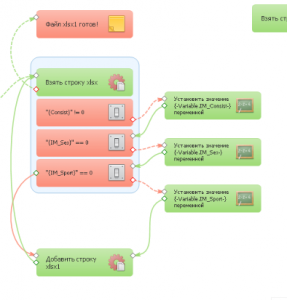
Задача - взять в одной таблице все значения, сравнить пару переменных, поменять пару значений и записать всё получившееся в другую таблицу.
Выполняется почему-то очень медленно.
Пробовал и xlsx и csv на вход и на выход, всё-равно медленно.
В таблице около 15тыс строк. Таблица до столбца AG это 34 столбца получается.
Неужели так сложно зенке взять строку со всех столбцов и записать её в другой файл, что так долго делает?
Обрабатывает это всё около часа на 20 потоках. Может я что делаю не так?