



- Регистрация
- 06.08.2013
- Сообщения
- 94
- Благодарностей
- 4
- Баллы
- 8
Hi,
I try to extract content with HtmlAgilityPack :
I have this error :

I have installed the latest version of HtmlAgilityPack net45
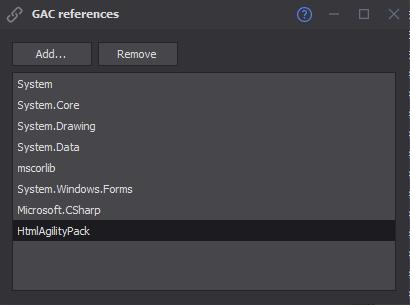
I try to extract content with HtmlAgilityPack :
C#:
using HtmlAgilityPack;
string htmlContent = project.Variables["DOM"].Value;
var doc = new HtmlDocument();
doc.LoadHtml(htmlContent);
var article = doc.DocumentNode.SelectSingleNode("//body");
// Remove all unwanted elements within the article
foreach (var node in article.SelectNodes("//*[not(starts-with(name(),'h')) and not(name()='h') and not(name()='ul') and not(name()='li') and not(name()='strong') and not(name()='b')]"))
{
node.Remove();
}
// Print the article content with only the desired tags
string extractedContent = project.Variables["content"].Value;I have installed the latest version of HtmlAgilityPack net45
