



- Регистрация
- 02.12.2014
- Сообщения
- 135
- Благодарностей
- 119
- Баллы
- 43
The parser includes two templates:
It navigates to the video page in the browser, extracts the description, and title.
Rutube ID Parser
To kickstart, it feeds the ID of one video. Then the template parses the IDs of recommended videos.
First, you need to parse the IDs. I managed to get around 2.5 million in a week. Then, run the template for video parsing. Ideally, both templates can work together - parsing IDs will always be faster than descriptions and titles.
The data is stored in a MySQL database because storing such a huge amount of information in files is simply not optimal. To work, you will need to install the database itself and phpMyAdmin (optional, for convenience).
Installation method #1:
Download the installer from https://dev.mysql.com/downloads/installer/. For phpMyAdmin, you will need PHP and a web server (Apache or nginx). You can download ready-made LAMP bundles like Wamp, Xampp, etc.
Installation method #2:
Install Docker Desktop. Prepare the docker-compose.yml file, navigate to the directory with this file, and execute the command
Create a table with the following structure:
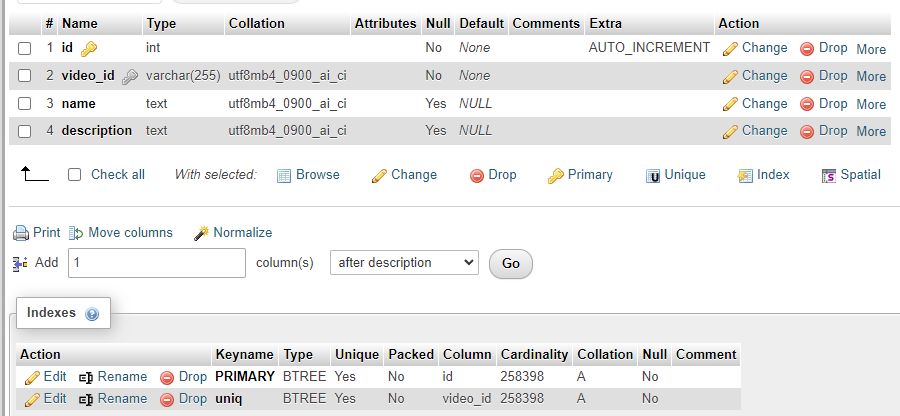
Create a unique index for video_id to avoid duplicates. And, of course, a primary index for auto-increment.
Naturally, indexes need to be created before populating the table with data.
The database is ready. Add one entry manually with the first ID. https://rutube.ru/video/b95b7041ad1c3dbde2730be0496ab7cb/ - extract the ID. Take any video and copy the ID. Then run Rutube ID Parser. Once at least the first 1000 are available, you can start Rutube Video Parser.
- Video description and title parser.
- Recommended videos parser.
It navigates to the video page in the browser, extracts the description, and title.
Rutube ID Parser
To kickstart, it feeds the ID of one video. Then the template parses the IDs of recommended videos.
First, you need to parse the IDs. I managed to get around 2.5 million in a week. Then, run the template for video parsing. Ideally, both templates can work together - parsing IDs will always be faster than descriptions and titles.
The data is stored in a MySQL database because storing such a huge amount of information in files is simply not optimal. To work, you will need to install the database itself and phpMyAdmin (optional, for convenience).
Installation method #1:
Download the installer from https://dev.mysql.com/downloads/installer/. For phpMyAdmin, you will need PHP and a web server (Apache or nginx). You can download ready-made LAMP bundles like Wamp, Xampp, etc.
Installation method #2:
Install Docker Desktop. Prepare the docker-compose.yml file, navigate to the directory with this file, and execute the command
docker-compose up. After starting the containers, phpMyAdmin will be available at localhost:8080.Create a table with the following structure:
Create a unique index for video_id to avoid duplicates. And, of course, a primary index for auto-increment.
Naturally, indexes need to be created before populating the table with data.
The database is ready. Add one entry manually with the first ID. https://rutube.ru/video/b95b7041ad1c3dbde2730be0496ab7cb/ - extract the ID. Take any video and copy the ID. Then run Rutube ID Parser. Once at least the first 1000 are available, you can start Rutube Video Parser.
- Тема статьи
- Парсинг
Вложения
-
390 байт Просмотры: 18
-
20,2 КБ Просмотры: 17
-
16,5 КБ Просмотры: 14