

- Регистрация
- 30.11.2020
- Сообщения
- 495
- Благодарностей
- 311
- Баллы
- 63
Добрый день форум. Делюсь небольшим мануалом как получать списки необходимых для работы коллекций адресов url .
В процессе разработки каких либо решений (не важно в какой среде) порой встречается необходимость тестировать софт на каких то моделях. В текущем случае, например, как варианты сбор контактных данных, форм обратной связи, поиск форумов, пользовательских старниц или же страниц компаний и так можно продолжать до бесконечности.
Но все упирается либо в мощности либо в деньги либо во время. Если найти для теста списки адресов сайтов не проблема (сотни миллионов адресов в открытом доступе), то вот найти интересующующие коллекции по паттерну - это уже стоит денег (самое дешевое что я находил - от 199$ за 1 000 000 страниц по нужному Вам паттерну), а если паттерном несколько сотен?Собирать самостоятельно ссылки с сайтов - то еще занятие и очень сильно отвлекает ресурсы и время, да и структура сайтов неоднородна поэтому такой вариант не очень продуктивен.
Однако,все же есть множество доступных и бесплатных вариантов получения таких коллекций и с одним из них я Вас познакомлю. Это файлы столбчатого индекса от компании Common Crawl. Кому интересно - добро пожаловать под кат.

######
Те кто не знаком с СС(Common Crawler) загляните под спойлер.
Коллекции данных СС "выкатывает" обычно раз в месяц, быват, но редко - раз в два месяца. Коллекции содержат как содержание самих веб страниц, так и различные наборы, такие как индексы адресов сайтов и их страниц, robots, графы и многое другое. Данных не просто много, их крайне много и более чем достаточно для "обкатки" своих теорий, скриптов и ПО. К примеру крайняя выкладка содержит в себе данные 3.15 миллиардов веб страниц, объемом 400 TИ несжатого контента.Проверено более 40 миллионов хостов. Напомню - данные ежемесячные (реже двухмесячные), собираются с 2011 года.
В этой статье рассмотрим работу со столбчатым индексом CDX.
Ежемесячные коллекции, точнее ссылки на них публикуются по адресу https://commoncrawl.org/connect/blog/
Пока я готовил материал для статьи - вышло обновление графов >325миллионов нод. А также ранжированный список из 88 милионов веб адресов
#####
Вернемся с CDX. Для начала нам необходимо получить сам список архивов что бы скачать
Переходим в таблицу и скачиваем архив со строки отмеченной зеленым холдером
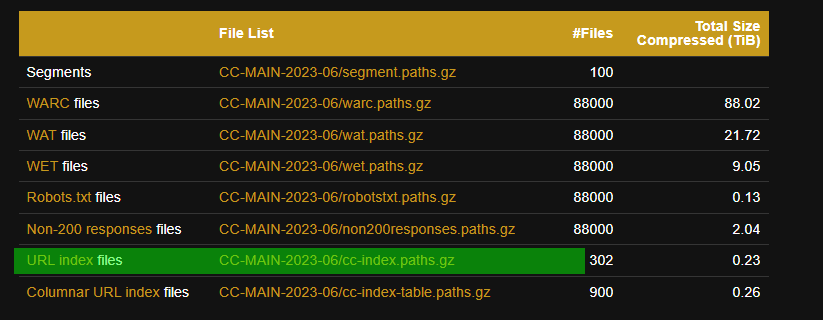
Разархивируем и открываем в своем редакторе, выглядит так
Последние два файла нас не интересуют, только первые 300. Загоняем их в любой доунлоадер который Вы используете и скачиваем.
(ВНИМАНИЕ - Не забывайте про объем архивов - 0,23 Тб)
(ВНИМАНИЕ 2 - После распаковки объем каждого файла вырастает от 5 до 7 раз, рекомендую последовательную распаковку и обработку)
Что представляет из себя файл столбчатого индекса после распаковки?
Это от 11 до 18 миллионов строк такого типа
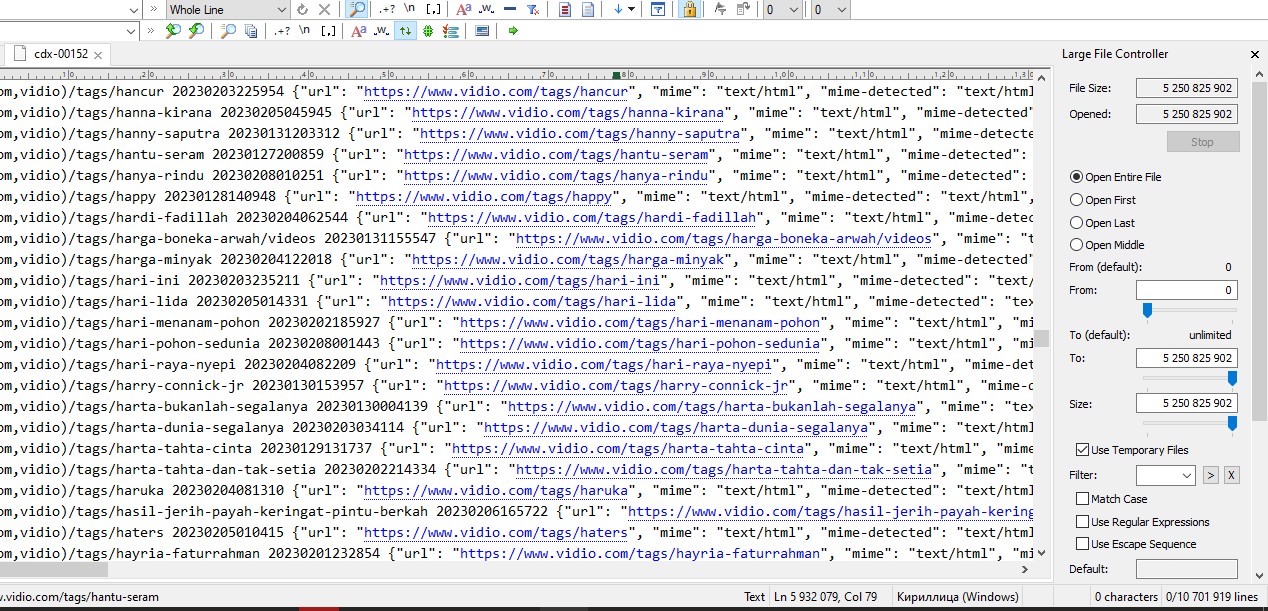
Как я уже писал на самом сайте в разделе https://commoncrawl.org/the-data/ есть необходимы скрипты и программы для обработки на любой вкус и цвет. Но главный вопрос который меня волновал - это вопрос места на винте, а также куча ненужного мусора присутствующего в файлах. Поэтому, для дальнейшего поиска нужных коллекций нужно конечно почистить. Из 43 полей хватает только 3 - сам сайт (в начале, в обратной нотации) уникальная ссылка на страницу сайта и как я чуть позже дополнил - языковые параметры сайта. (По тексту объясню дальше зачем).
Готовые решения мне не подошли, нужен был кастом, поэтому собрал на ZP. Требование были простые -сделать выборку как указано выше и как можно быстрей. Получилось приемлимо - ~2 минуты на один 5-7 Гб файл.
Видеопруф - чтобы исключить вопросы новичков - "Действительно ZP может обрабатывать файлы большого размера с высокой скоростью".
Продолжаем. Для тех кто не смотрел видео - файлы по 6 и выше гигабайт действительно обрабатываются в течении ~2 минут ( при этом у меня HDD I5 8GB RAM и было запущено дополнительно несколько приложений. Как написал один пользователь шаблона у него обработка занимала около 20 секунд.)
На выходе получаем такой вот файл
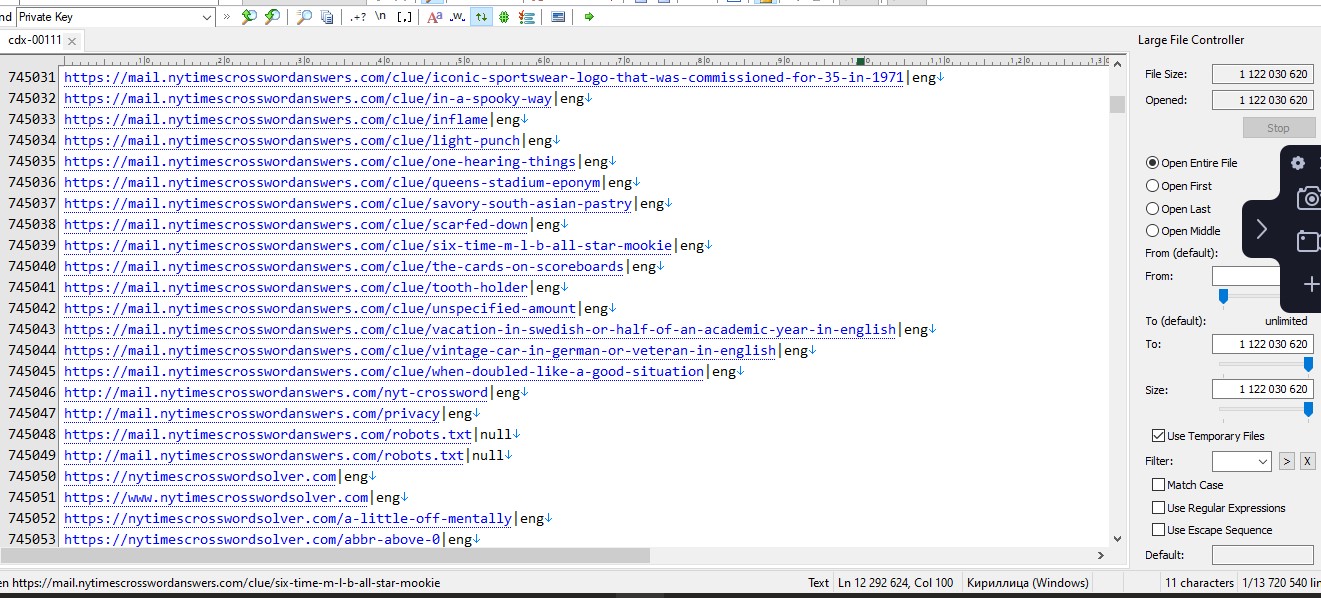
Также, я показал на видео, скрипт собрал дополнительно 338К+ уникальных доменов. Это только с двух файлов. При этом после обработки размер файлов удалось снизить в 6 раз путем удаления ненужного хлама (Кто не смотрел - гляньте видео).
С учетом того что файлов 300, а затраты составляют 2 минуты на файл, то поставив вечером на обработку - утром можно получить уже готовые для дальнейшей работы данные с 3+ миллиардами ссылок сайтов.
После очистки файлов и снижения их объемов, думаю что уже ни для кого не станет проблемой поиск паттернов для своих нужд. Как писал в самом начале - для различной работы требуются различные ссылки - кто то ищет форумы, кто то объявления, кто то пользовательские данные и.т.д.
Я же хочу показать обработку на одном паттерне который близок многим пользователям на форуме - это поиск контактных форм либо контактных страниц для сбора и или обогащения своих баз данных.
Смотрим пруф и обращаем внимание на скорость поиска.
Если кто не смотрел видео, поиск в 2 файлах с 20+ миллионами строк с одним паттерном "contact" занял всего 40 секунд. Для поиска по всем 300 файлам времени уйдет от часу до двух. Конечно можно ускорить еще раз в 5, но пока не к спеху.
Теперь об языковых параметрах. После того как Вы соберете по паттернам ссылки, Вам возможна необходима будет обработка страниц и знания языка контента. Ведь данные для реджексов работающие на одном языке не будут работать на другом ипонимание что применять позволит заранее подготовить нужные словари.
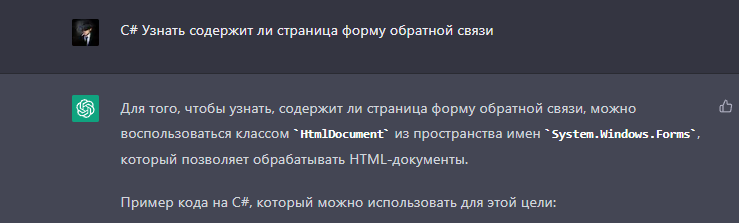
Кстати.... По поиску форм на страницах сайта - ЖПТ в помощь :-)")
 #####
#####
Подводя итоги можно сказать следующее - не всегда необходимо что то покупать или тратить кучу времени на поиск нужных данных (в текущем случае - прямых ссылок на нужные страницы) достаточно просто немного подойти иначе к вопросу.
Следует отметить, что работа с CDX это микроскопический мизер возможностей которые предлагает СС и если тема работы с большими данными окажется востребованной я постараюсь подготовить цикл статей по работе уже с WARC коллекциями.
#####
Благодарю за внимание.
Кто работает с Common Crawler - буду рад обратной связи, кто работает с большими данными или же у кого есть какие либо вопросы по теме - пишите в Телеграм @Shock_cybersystems
В процессе разработки каких либо решений (не важно в какой среде) порой встречается необходимость тестировать софт на каких то моделях. В текущем случае, например, как варианты сбор контактных данных, форм обратной связи, поиск форумов, пользовательских старниц или же страниц компаний и так можно продолжать до бесконечности.
Но все упирается либо в мощности либо в деньги либо во время. Если найти для теста списки адресов сайтов не проблема (сотни миллионов адресов в открытом доступе), то вот найти интересующующие коллекции по паттерну - это уже стоит денег (самое дешевое что я находил - от 199$ за 1 000 000 страниц по нужному Вам паттерну), а если паттерном несколько сотен?Собирать самостоятельно ссылки с сайтов - то еще занятие и очень сильно отвлекает ресурсы и время, да и структура сайтов неоднородна поэтому такой вариант не очень продуктивен.
Однако,все же есть множество доступных и бесплатных вариантов получения таких коллекций и с одним из них я Вас познакомлю. Это файлы столбчатого индекса от компании Common Crawl. Кому интересно - добро пожаловать под кат.
######
Те кто не знаком с СС(Common Crawler) загляните под спойлер.
Common Crawl — это некоммерческая организация ) , которая сканирует Интернет и бесплатно предоставляет свои архивы и наборы данных общественности. Веб-архив Common Crawl состоит из эксабайт данных, собранных с 2011 года. Как правило, сканирование выполняется каждый месяц.
Сканеры организации соблюдают политики nofollow и robots.txt . Открытый исходный код для обработки набора данных Common Crawl общедоступен.
Набор данных Common Crawl включает работу, защищенную авторским правом, и распространяется из США в соответствии с требованиями добросовестного использования . Исследователи в других странах использовали такие методы, как перетасовка предложений или обращение к общему набору данных сканирования, чтобы обойти закон об авторском праве в других правовых юрисдикциях.
Наборами данных СС пользуются крупнейшие исследовательские институты, агентства рекламы и веб-аналитики, вебразработчики и частные исследования.
На основе СС тренировались нейроные сети Open AI GPT-3/4 (тык).
На сайте содержатся ссылки на сотни исследований, на наборы данных, на программы и скрипты для обработки данных, на разных языках программирования и с использованием различным вариантов обработки - станция, лептоп, сервер
Сайт СС - https://commoncrawl.org/
Таким образом, упускать возможности открытых коллекций данных СС - в настоящее время неблагоразумно.
Сканеры организации соблюдают политики nofollow и robots.txt . Открытый исходный код для обработки набора данных Common Crawl общедоступен.
Набор данных Common Crawl включает работу, защищенную авторским правом, и распространяется из США в соответствии с требованиями добросовестного использования . Исследователи в других странах использовали такие методы, как перетасовка предложений или обращение к общему набору данных сканирования, чтобы обойти закон об авторском праве в других правовых юрисдикциях.
Наборами данных СС пользуются крупнейшие исследовательские институты, агентства рекламы и веб-аналитики, вебразработчики и частные исследования.
На основе СС тренировались нейроные сети Open AI GPT-3/4 (тык).
На сайте содержатся ссылки на сотни исследований, на наборы данных, на программы и скрипты для обработки данных, на разных языках программирования и с использованием различным вариантов обработки - станция, лептоп, сервер
Сайт СС - https://commoncrawl.org/
Таким образом, упускать возможности открытых коллекций данных СС - в настоящее время неблагоразумно.
Коллекции данных СС "выкатывает" обычно раз в месяц, быват, но редко - раз в два месяца. Коллекции содержат как содержание самих веб страниц, так и различные наборы, такие как индексы адресов сайтов и их страниц, robots, графы и многое другое. Данных не просто много, их крайне много и более чем достаточно для "обкатки" своих теорий, скриптов и ПО. К примеру крайняя выкладка содержит в себе данные 3.15 миллиардов веб страниц, объемом 400 TИ несжатого контента.Проверено более 40 миллионов хостов. Напомню - данные ежемесячные (реже двухмесячные), собираются с 2011 года.
В этой статье рассмотрим работу со столбчатым индексом CDX.
Ежемесячные коллекции, точнее ссылки на них публикуются по адресу https://commoncrawl.org/connect/blog/
Пока я готовил материал для статьи - вышло обновление графов >325миллионов нод. А также ранжированный список из 88 милионов веб адресов
#####
СС часто выкладывает открытые данные по сайтом с ранжированием по Harmonic Centrality и PageRank.
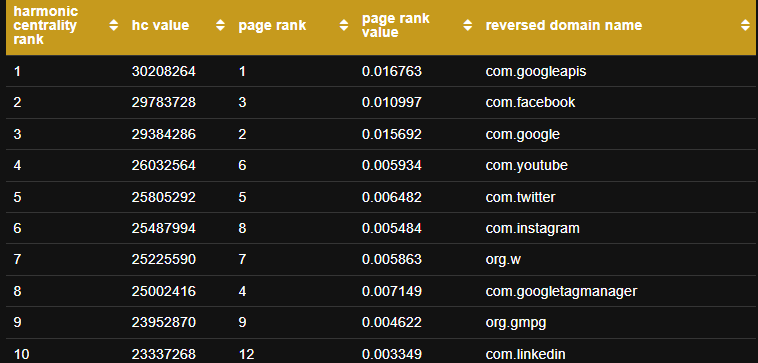
На сайте Вы можете скачать архив с этими данными.
Вес архива - 1,9 Гб и 5,65 в распакованном.
После распаковки выглядит таким образом
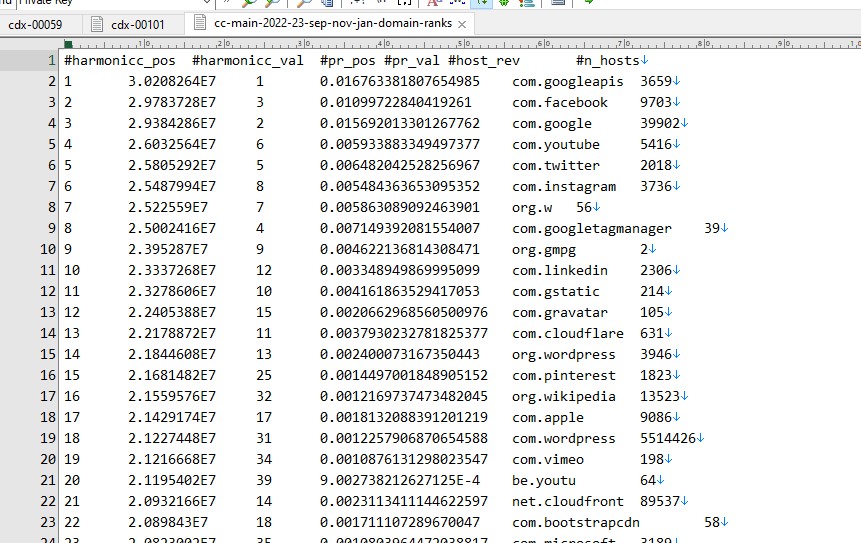
Вы можете обработать его так как Вам удобней, мне же это потребовалось сделать для статьи чтобы понять сколько будет "весить" список только из доменов. Выбрать домены не проблема, но напрягло то что они в обратной нотации. Париться не стал - "постучался" к ИИ в чатЖПТ
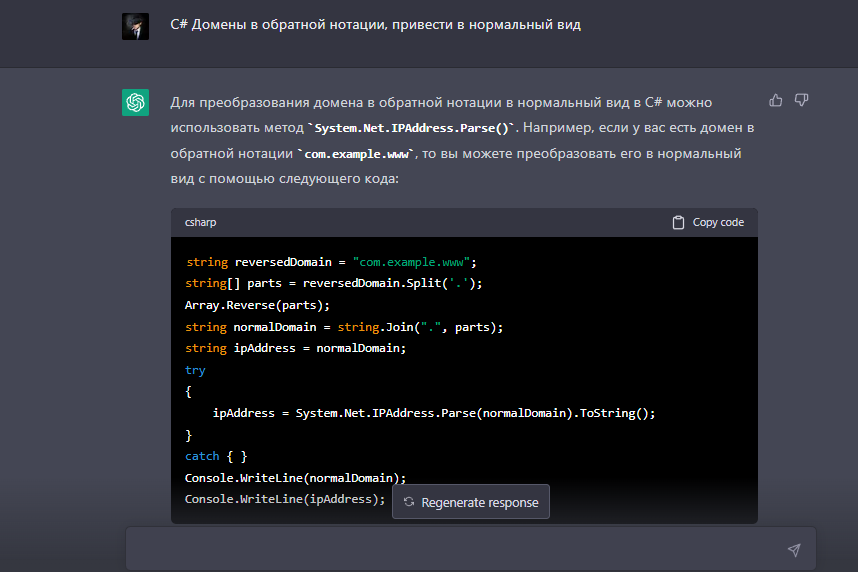
Ну и сам адаптированный код для ZP -Вам нужно только указать путь к разархивированному файлу и путь куда сохранить результат, танцы с бубнами отсутствуют.
На выходе получилось 1,6 Гб в таком виде

На сайте Вы можете скачать архив с этими данными.
Вес архива - 1,9 Гб и 5,65 в распакованном.
После распаковки выглядит таким образом
Вы можете обработать его так как Вам удобней, мне же это потребовалось сделать для статьи чтобы понять сколько будет "весить" список только из доменов. Выбрать домены не проблема, но напрягло то что они в обратной нотации. Париться не стал - "постучался" к ИИ в чатЖПТ
Ну и сам адаптированный код для ZP -Вам нужно только указать путь к разархивированному файлу и путь куда сохранить результат, танцы с бубнами отсутствуют.
Обработка списка ранжирования:
string path = @"C:\cc-main-2022-23-sep-nov-jan-domain-ranks.txt";//Исходный файл
string path_out = @"C:\clean_domains.txt";//Куда записывать
System.IO.StreamWriter writer = new System.IO.StreamWriter(path_out, true);
using (StreamReader file = new System.IO.StreamReader(path))
{
string line;
while ((line = file.ReadLine()) != null)
{
if (line.Contains('.'))
{
string[] text = (line).Split(' ');
string reversedDomain = text[4];
string[] parts = reversedDomain.Split('.');
Array.Reverse(parts);
string normalDomain = string.Join(".", parts);
string ipAddress = normalDomain;
writer.WriteLine(normalDomain);
}
}
}
writer.Dispose();Вернемся с CDX. Для начала нам необходимо получить сам список архивов что бы скачать
Переходим в таблицу и скачиваем архив со строки отмеченной зеленым холдером
Разархивируем и открываем в своем редакторе, выглядит так
Последние два файла нас не интересуют, только первые 300. Загоняем их в любой доунлоадер который Вы используете и скачиваем.
(ВНИМАНИЕ - Не забывайте про объем архивов - 0,23 Тб)
(ВНИМАНИЕ 2 - После распаковки объем каждого файла вырастает от 5 до 7 раз, рекомендую последовательную распаковку и обработку)
Что представляет из себя файл столбчатого индекса после распаковки?
Это от 11 до 18 миллионов строк такого типа
Код:
com,vidio)/tags/harga-boneka-arwah/videos 20230131155547 {"url": "https://www.vidio.com/tags/harga-boneka-arwah/videos", "mime": "text/html", "mime-detected": "text/html", "status": "200", "digest": "K2BVK2N3V3LLRHPW47WKDABCKSQ46BXF", "length": "11090", "offset": "1047650524", "filename": "crawl-data/CC-MAIN-2023-06/segments/1674764499888.62/warc/CC-MAIN-20230131154832-20230131184832-00025.warc.gz", "charset": "UTF-8", "languages": "ind"}
com,vidio)/tags/harga-minyak 20230204122018 {"url": "https://www.vidio.com/tags/harga-minyak", "mime": "text/html", "mime-detected": "text/html", "status": "200", "digest": "W6WYJFUCM3CYJ6FAOM4K2M3WS22EDSLR", "length": "18299", "offset": "1062410909", "filename": "crawl-data/CC-MAIN-2023-06/segments/1674764500126.0/warc/CC-MAIN-20230204110651-20230204140651-00629.warc.gz", "charset": "UTF-8", "languages": "ind"}
com,vidio)/tags/hari-ini 20230203235211 {"url": "https://www.vidio.com/tags/hari-ini", "mime": "text/html", "mime-detected": "text/html", "status": "200", "digest": "GKEQSTZFLBHQYJTVIMY76PGZQVKP4IYQ", "length": "18615", "offset": "1061194561", "filename": "crawl-data/CC-MAIN-2023-06/segments/1674764500076.87/warc/CC-MAIN-20230203221113-20230204011113-00017.warc.gz", "charset": "UTF-8", "languages": "ind"}
com,vidio)/tags/hari-lida 20230205014331 {"url": "https://www.vidio.com/tags/hari-lida", "mime": "text/html", "mime-detected": "text/html", "status": "200", "digest": "QVJZGQEKP5TJC47QG3ASACPXKGSCVNPO", "length": "19245", "offset": "1062831028", "filename": "crawl-data/CC-MAIN-2023-06/segments/1674764500158.5/warc/CC-MAIN-20230205000727-20230205030727-00269.warc.gz", "charset": "UTF-8", "languages": "ind"}
com,vidio)/tags/hari-menanam-pohon 20230202185927 {"url": "https://www.vidio.com/tags/hari-menanam-pohon", "mime": "text/html", "mime-detected": "text/html", "status": "200", "digest": "TGDO45QG6HEQGIE3KSQK7ID4S45KOBSD", "length": "11465", "offset": "1052704202", "filename": "crawl-data/CC-MAIN-2023-06/segments/1674764500035.14/warc/CC-MAIN-20230202165041-20230202195041-00807.warc.gz", "charset": "UTF-8", "languages": "ind"}
com,vidio)/tags/hari-pohon-sedunia 20230208001443 {"url": "https://www.vidio.com/tags/hari-pohon-sedunia", "mime": "text/html", "mime-detected": "text/html", "status": "200", "digest": "QJJWT2WFOMA52J73UJPQAD6YFDRWZTFY", "length": "11860", "offset": "1066391366", "filename": "crawl-data/CC-MAIN-2023-06/segments/1674764500664.85/warc/CC-MAIN-20230207233330-20230208023330-00203.warc.gz", "charset": "UTF-8", "languages": "ind"}
com,vidio)/tags/hari-raya-nyepi 20230204082209 {"url": "https://www.vidio.com/tags/hari-raya-nyepi", "mime": "text/html", "mime-detected": "text/html", "status": "200", "digest": "GSKULSRVLSR3T5LHMZID3V3CCDMLCFAU", "length": "18878", "offset": "1079732905", "filename": "crawl-data/CC-MAIN-2023-06/segments/1674764500095.4/warc/CC-MAIN-20230204075436-20230204105436-00016.warc.gz", "charset": "UTF-8", "languages": "ind"}Как я уже писал на самом сайте в разделе https://commoncrawl.org/the-data/ есть необходимы скрипты и программы для обработки на любой вкус и цвет. Но главный вопрос который меня волновал - это вопрос места на винте, а также куча ненужного мусора присутствующего в файлах. Поэтому, для дальнейшего поиска нужных коллекций нужно конечно почистить. Из 43 полей хватает только 3 - сам сайт (в начале, в обратной нотации) уникальная ссылка на страницу сайта и как я чуть позже дополнил - языковые параметры сайта. (По тексту объясню дальше зачем).
Готовые решения мне не подошли, нужен был кастом, поэтому собрал на ZP. Требование были простые -сделать выборку как указано выше и как можно быстрей. Получилось приемлимо - ~2 минуты на один 5-7 Гб файл.
Видеопруф - чтобы исключить вопросы новичков - "Действительно ZP может обрабатывать файлы большого размера с высокой скоростью".
На выходе получаем такой вот файл
Также, я показал на видео, скрипт собрал дополнительно 338К+ уникальных доменов. Это только с двух файлов. При этом после обработки размер файлов удалось снизить в 6 раз путем удаления ненужного хлама (Кто не смотрел - гляньте видео).
С учетом того что файлов 300, а затраты составляют 2 минуты на файл, то поставив вечером на обработку - утром можно получить уже готовые для дальнейшей работы данные с 3+ миллиардами ссылок сайтов.
После очистки файлов и снижения их объемов, думаю что уже ни для кого не станет проблемой поиск паттернов для своих нужд. Как писал в самом начале - для различной работы требуются различные ссылки - кто то ищет форумы, кто то объявления, кто то пользовательские данные и.т.д.
Я же хочу показать обработку на одном паттерне который близок многим пользователям на форуме - это поиск контактных форм либо контактных страниц для сбора и или обогащения своих баз данных.
Смотрим пруф и обращаем внимание на скорость поиска.
Если кто не смотрел видео, поиск в 2 файлах с 20+ миллионами строк с одним паттерном "contact" занял всего 40 секунд. Для поиска по всем 300 файлам времени уйдет от часу до двух. Конечно можно ускорить еще раз в 5, но пока не к спеху.
Теперь об языковых параметрах. После того как Вы соберете по паттернам ссылки, Вам возможна необходима будет обработка страниц и знания языка контента. Ведь данные для реджексов работающие на одном языке не будут работать на другом ипонимание что применять позволит заранее подготовить нужные словари.
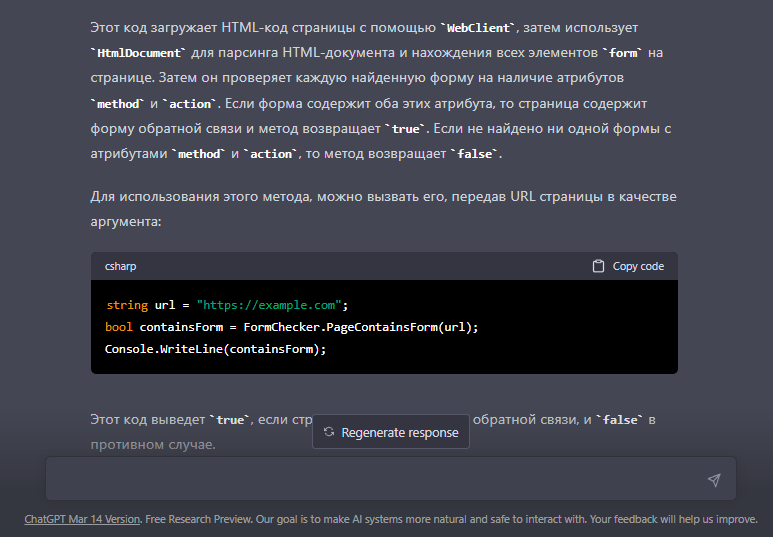
Кстати.... По поиску форм на страницах сайта - ЖПТ в помощь
Совет ЖПТ:
using System;
using System.Net;
using System.Windows.Forms;
public class FormChecker
{
public static bool PageContainsForm(string url)
{
WebClient client = new WebClient();
string htmlCode = client.DownloadString(url);
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(htmlCode);
foreach (HtmlElement form in doc.GetElementsByTagName("form"))
{
if (form.GetAttribute("method") != null && form.GetAttribute("action") != null)
{
// Если найдена форма с атрибутами method и action, то страница содержит форму обратной связи
return true;
}
}
return false;
}
}Подводя итоги можно сказать следующее - не всегда необходимо что то покупать или тратить кучу времени на поиск нужных данных (в текущем случае - прямых ссылок на нужные страницы) достаточно просто немного подойти иначе к вопросу.
Следует отметить, что работа с CDX это микроскопический мизер возможностей которые предлагает СС и если тема работы с большими данными окажется востребованной я постараюсь подготовить цикл статей по работе уже с WARC коллекциями.
#####
Благодарю за внимание.
Кто работает с Common Crawler - буду рад обратной связи, кто работает с большими данными или же у кого есть какие либо вопросы по теме - пишите в Телеграм @Shock_cybersystems
Для запуска проектов требуется программа ZennoPoster.
Это основное приложение, предназначенное для выполнения автоматизированных шаблонов действий (ботов).
Подробнее...
Для того чтобы запустить шаблон, откройте программу ZennoPoster. Нажмите кнопку «Добавить», и выберите файл проекта, который хотите запустить.
Подробнее о том, где и как выполняется проект.
