

Помогите чекнуть 2 миллиарда строк. Как лучше?
- Автор темы backoff
- Дата начала
Mikhail B.
Moderator
- Регистрация
- 23.12.2014
- Сообщения
- 14 320
- Благодарностей
- 5 424
- Баллы
- 113
Списки не вывозят такие скорости. Только БД. Ее еще оптимизировать придетсяОфигеть сайтег! Где ты такие находишь?
Проверенные записывать в список и сверять, если есть, то брать следующий. Неподойдет?
+ может банально в интернет уперется
Ну и сама зенка может тупо не потянуть.
- Регистрация
- 20.04.2015
- Сообщения
- 5 925
- Благодарностей
- 6 389
- Баллы
- 113
это на много больше мороки и информации придется обрабатывать. никак не подойдетПроверенные записывать в список и сверять
нужно как-то просто всем потокам передавать счетчик переменной, как это сделать я не знаю.
но мысль такая, есть переменная, она = 1 на старте, и каждый поток который берет ее к себе, добавляет +1 и возвращает в глобал обратно для следующего потока, который будет так же брать ее.
не не не, не так, не правильно поняли походу.Списки не вывозят такие скорости. Только БД. Ее еще оптимизировать придется
+ может банально в интернет уперется
Ну и сама зенка может тупо не потянуть.
мне надо лишь передавать значение переменной, то есть надо чтоб у каждого потока была своя цифра в переменной, чтоб не было повторений
Lord_Alfred
Client
- Регистрация
- 09.10.2015
- Сообщения
- 3 916
- Благодарностей
- 3 856
- Баллы
- 113
Тоже некоторое время назад искал как быстрее всего делать проверку на 200 ответ сервера: https://zennolab.com/discussion/threads/kak-prochitat-pervye-n-bajt-http-head-zaprosa-s-ispolzovaniem-proxy-bystraja-proverka-na-404-error.54696/
Но готового решения там так и не нашел. Но упомянуть тут тот топик стоит, ибо задачи схожи и вдруг тут найдутся те, кто уже имеют такие готовые инструменты )
Но готового решения там так и не нашел. Но упомянуть тут тот топик стоит, ибо задачи схожи и вдруг тут найдутся те, кто уже имеют такие готовые инструменты )
- Регистрация
- 20.04.2015
- Сообщения
- 5 925
- Благодарностей
- 6 389
- Баллы
- 113
ну есть конечно более тупой варик, это сделать текстовый файл с 2 млн строк (500 файлов таких) где разбить число в 2 млрд и брать от туда числа как из списка, ну это лол конечно, я думаю должен быть более элегантный способ  :-)")
one
Client
- Регистрация
- 22.09.2015
- Сообщения
- 6 793
- Благодарностей
- 1 264
- Баллы
- 113
Ну а если не в файл а в БД?ну есть конечно более тупой варик, это сделать текстовый файл с 2 млн строк (500 файлов таких) где разбить число в 2 млрд и брать от туда числа как из списка, ну это лол конечно, я думаю должен быть более элегантный способ
Lord_Alfred
Client
- Регистрация
- 09.10.2015
- Сообщения
- 3 916
- Благодарностей
- 3 856
- Баллы
- 113
СУБД юзать надо, никаких файлов/списков/таблиц. Сразу производительность с ними просядет в разы.ну есть конечно более тупой варик, это сделать текстовый файл с 2 млн строк (500 файлов таких) где разбить число в 2 млрд и брать от туда числа как из списка, ну это лол конечно, я думаю должен быть более элегантный способ
Другой вопрос как я уже выше писал - что нужно проверять не весь ответ сервера целиком, чтоб не забивать канал получением кучи ненужной информации.
PS: уже 100% есть такого рода решения, просто мы о них не в курсе) Зенка тут будет только усложнять всё и тормозить.
- Регистрация
- 20.04.2015
- Сообщения
- 5 925
- Благодарностей
- 6 389
- Баллы
- 113
ну можно сделать РАМ диск, и все файлы туда переместить, тормозов не будет.
или админов просить чтоб в зенке делали надстройку, сколько символов получать при гет запросе
тоже так думаю, надо прогеров привлекатьуже 100% есть такого рода решения, просто мы о них не в курсе)
или админов просить чтоб в зенке делали надстройку, сколько символов получать при гет запросе
HastaLaVista
Client
- Регистрация
- 29.10.2018
- Сообщения
- 162
- Благодарностей
- 144
- Баллы
- 43
Возможно подойдет анализатор базы и ссылок хрумера, там при 1000 потоков (если Инет и роутер потянет) месяца за полтора прочекает. Или делать на A-Parsere.
В любом случае тут очень второстепенно - списки, базы данных или файлы. Все уткнется в скорость работы с Интернетом, производительность сетевого оборудования и максимальное кол-во потоков задолго до того, как скажутся ограничения скорости файловой системы.
В любом случае тут очень второстепенно - списки, базы данных или файлы. Все уткнется в скорость работы с Интернетом, производительность сетевого оборудования и максимальное кол-во потоков задолго до того, как скажутся ограничения скорости файловой системы.
alekwuy
Client
- Регистрация
- 06.04.2013
- Сообщения
- 1 631
- Благодарностей
- 461
- Баллы
- 83
Если ты будешь делать 1000 запросов в секунду, а ты не сможешь потому что тебя забанят как ддосера, то нужно будет 23 дня что бы это все спарсить
а если делать 100 запросов с сек. что более реально то нужно 230 дней
затея так себе)
ты решил вики прочекать?
а если делать 100 запросов с сек. что более реально то нужно 230 дней
затея так себе)
ты решил вики прочекать?
HastaLaVista
Client
- Регистрация
- 29.10.2018
- Сообщения
- 162
- Благодарностей
- 144
- Баллы
- 43
Кстати, еще один немаловажный вопрос - сайт за Cloudflare? Как справедливо заметили выше - обращение к 2 млрд. страниц за любое приемлемое для практических целей время сайт однозначно воспримет как DDOS.
Поэтому задачка вырисовывается сильно комплексная, куча прокси, быстрый парсер и т.п. Ну вообщем спамить надо спаммерами, парсить парсерами
Поэтому задачка вырисовывается сильно комплексная, куча прокси, быстрый парсер и т.п. Ну вообщем спамить надо спаммерами, парсить парсерами
- Регистрация
- 20.04.2015
- Сообщения
- 5 925
- Благодарностей
- 6 389
- Баллы
- 113
и такс.
1. проверил, сайт не на клауде, спасибо за подсказку
2. покупать А-парсер ради этого - шляпа
3. никакие данные нигде хранить не надо
ну как бы надо, но далеко не все, то есть как парс должен проходить. заходим на страницу
site.ru/papka/1/
site.ru/papka/2/
site.ru/papka/3/
и тп
то есть нам тупо надо как-то во все потоки передавать только цифры
ооочень много страниц с 404 хедером, и мало с 200, поэтому мы будем только сохранять те страницы, которые отдали 200
в 1 поток за 20 + - минут проверил 50к страниц
как-то так, нужна логика подстановки нужной цифры, вот и все
1. проверил, сайт не на клауде, спасибо за подсказку
2. покупать А-парсер ради этого - шляпа
3. никакие данные нигде хранить не надо
ну как бы надо, но далеко не все, то есть как парс должен проходить. заходим на страницу
site.ru/papka/1/
site.ru/papka/2/
site.ru/papka/3/
и тп
то есть нам тупо надо как-то во все потоки передавать только цифры
ооочень много страниц с 404 хедером, и мало с 200, поэтому мы будем только сохранять те страницы, которые отдали 200
в 1 поток за 20 + - минут проверил 50к страниц
как-то так, нужна логика подстановки нужной цифры, вот и все
HastaLaVista
Client
- Регистрация
- 29.10.2018
- Сообщения
- 162
- Благодарностей
- 144
- Баллы
- 43
Примерно понятно. Т.е. есть сайт на котором теоретически может быть до 2 млрд. стр. с нужной инфой, но реально есть например только 100 000. Нужно перебрать все 2 млрд. комбинаций (точнее видимо 2 в 31 степени страниц  ;-)") , чтобы спарсить только те, которые есть реально.
, чтобы спарсить только те, которые есть реально.
Напрашивается самое тупое решение - скрипт на php, который будет долбить этот сайт GET с последовательно увеличивающимися номерами страниц. В логе сервака будут все хедеры, в логе ошибок с 404 кодом - только по обращениям к несуществующим страницам. Даже зенки не надо, запустил кучу скриптов по разным диапазонам страниц каждый на всю толщину канала VPS и все.
С вероятностью 99% на вторые сутки многопотоковой долбежки (учитывая 20 минут на 50к страниц - 13000 часов ну пусть в сто потоков = 130 часов) админы сайта почуют неладное и начнут банить. Может начнет банить автоматом еще раньше, если есть скрипт автобана при куче ошибок 404 с одного IP. И опять вернемся к тому, с чего начали - как минимум хорошие прокси, т.е. все упирается не в скрипты и алгоритмы а в канал.
, чтобы спарсить только те, которые есть реально. Напрашивается самое тупое решение - скрипт на php, который будет долбить этот сайт GET с последовательно увеличивающимися номерами страниц. В логе сервака будут все хедеры, в логе ошибок с 404 кодом - только по обращениям к несуществующим страницам. Даже зенки не надо, запустил кучу скриптов по разным диапазонам страниц каждый на всю толщину канала VPS и все.
С вероятностью 99% на вторые сутки многопотоковой долбежки (учитывая 20 минут на 50к страниц - 13000 часов ну пусть в сто потоков = 130 часов) админы сайта почуют неладное и начнут банить. Может начнет банить автоматом еще раньше, если есть скрипт автобана при куче ошибок 404 с одного IP. И опять вернемся к тому, с чего начали - как минимум хорошие прокси, т.е. все упирается не в скрипты и алгоритмы а в канал.

Lord_Alfred
Client
- Регистрация
- 09.10.2015
- Сообщения
- 3 916
- Благодарностей
- 3 856
- Баллы
- 113
Зачем. Придумывать. Такую. Сложную. Логику?создать список диапазонов
0|1000000
1000000|2000000
2000000|3000000
каждый поток берет строку с диапазоном и левое число увеличивает на единицу.
Есть же СУБД

Просите @Mikhail B. чтоб тот подробно рассказал как многопоток в зенке с СУБД с похожей задаче забил весь канал и почти не использовал ресурсы (ЦП, ОЗУ)
Предположим, что в списке 2000 таких строк. каждый поток берет такую строку при старте и работает с ней какоето время и если не сравнял правое число с левым перезаписывает обратно в список, чтоб в следующий раз продолжить.Зачем. Придумывать. Такую. Сложную. Логику?
Есть же СУБД
Просите @Mikhail B. чтоб тот подробно рассказал как многопоток в зенке с СУБД с похожей задаче забил весь канал и почти не использовал ресурсы (ЦП, ОЗУ)
HastaLaVista
Client
- Регистрация
- 29.10.2018
- Сообщения
- 162
- Благодарностей
- 144
- Баллы
- 43
Что-то я в джунгли залез с php скриптами и т.п. Покумекал чуть-чуть, все вообще просто и никакой зенки, СУБД и прочего вообще не нужно.
Берем самый дохлый VPS из разряда 2 бакса в месяц и запускаем простейший shell скрипт -
#!/bin/bash
while read LINE; do
curl -o /dev/null --silent --head --write-out "%{http_code} $LINE\n" "$LINE"
done < url-list.txt
Curl при этом грузит только заголовки, поэтому на трафе можно сильно сэкономить. Все два миллиарда URLов делим на 100 разных файлов url-list.txt и запускаем скрипт во столько потоков, насколько хватит мощности канала сервера. Но повторюсь - основными проблемами при чеке 2 млрд. страниц будут баны от сервака который парсим (и я их ОЧЕНЬ сильно понимаю) и масштабы трафа. Внезапно может оказаться, что безлимитные тарифы вовсе не безлимитные если речь идет о трафе в десятки ТБ за несколько дней. Баны и объем трафа здесь намного сложнее, чем мелкие частные вопросы с обработкой и хранением результатов.
Покумекал чуть-чуть, все вообще просто и никакой зенки, СУБД и прочего вообще не нужно.Берем самый дохлый VPS из разряда 2 бакса в месяц и запускаем простейший shell скрипт -
#!/bin/bash
while read LINE; do
curl -o /dev/null --silent --head --write-out "%{http_code} $LINE\n" "$LINE"
done < url-list.txt
Curl при этом грузит только заголовки, поэтому на трафе можно сильно сэкономить. Все два миллиарда URLов делим на 100 разных файлов url-list.txt и запускаем скрипт во столько потоков, насколько хватит мощности канала сервера. Но повторюсь - основными проблемами при чеке 2 млрд. страниц будут баны от сервака который парсим (и я их ОЧЕНЬ сильно понимаю) и масштабы трафа. Внезапно может оказаться, что безлимитные тарифы вовсе не безлимитные если речь идет о трафе в десятки ТБ за несколько дней. Баны и объем трафа здесь намного сложнее, чем мелкие частные вопросы с обработкой и хранением результатов.
inilim
Client
- Регистрация
- 16.09.2017
- Сообщения
- 441
- Благодарностей
- 170
- Баллы
- 43
Geograph
Client
- Регистрация
- 16.02.2014
- Сообщения
- 209
- Благодарностей
- 113
- Баллы
- 43
На C# можно такое написать. Без использования зенки, на компилируемом C#. Отсылать только HEAD-запрос, чтобы было быстрее и не качать лишнего.
В принципе можно попробовать и используя curl в bash'е, но там будут проблемы с многопотоком.
В принципе можно попробовать и используя curl в bash'е, но там будут проблемы с многопотоком.
orka13
Client
- Регистрация
- 07.05.2015
- Сообщения
- 2 164
- Благодарностей
- 2 164
- Баллы
- 113
Не люби себе и людям мозги, именно так и сделай. Вангую что и так донора лучше парсить не больше чем 10...50 потоков, а то если админы не спят, то прикрутят гайки. А для такого количества потоков вполне хватит работы с списками-файлами по 3…10 мб. Даже RAM-диска не надо будет....Создавать списки с номерами и брать от туда, можно, но очень не хочется.
Делал подобное. Вот готовый шаблон. Номера залить в файлы:
Код:
\Input\part\Output_1.txt
\Input\part\Output_2.txt
…..
\Input\part\Output_2000.txtЭто закроет вопрос с нумерацией (инкрементом) в многопотоке.
Второй вариант: глобальная переменная с возможностью через входящие настройки задать номер начальный. Это если до этого работа прерывалась, но ты приблизительно знаешь с какого номера надо начинать (мы же и так сохраняем в файлы номера страниц рабочих и не рабочих). Логику строить так: первый поток инициирует эту переменную с заданным номером, а остальные потоки проверяют что если переменная уже инициирована, то увеличиваем ее значение при каждом обращении. Писать влом, есть на форуме пример хороший от Ростоникса.
Вложения
-
24,5 КБ Просмотры: 16
ssXXXss
Client
- Регистрация
- 23.12.2014
- Сообщения
- 7 379
- Благодарностей
- 2 039
- Баллы
- 113
C#:
var useragent = project.Variables["UserAgent"].Value;
int count = 0;
int count2 = 0;
for (int i = 0; i < 1000; i++)
{
if (Global.Variables.IsProjectMaker && !Global.Variables.IsDebugMode) throw new Exception();
if (((ZennoLab.InterfacesLibrary.ProjectModel.Collections.IContextExt)project.Context).IsInterrupted) throw new Exception();
var pages = new List<object>().Select(t => new { Count = default(int) }).ToList();
for (int j = count; j < count2 + 50; j++)
{
count++;
pages.Add(new { Count = count });
}
count2 = count;
var sb = new StringBuilder();
System.Threading.Tasks.Parallel.ForEach(pages, p =>
{
using (var request = new HttpRequest())
{
try
{
var url = "https://yandex.ru/";
request.ReconnectLimit = 3;
request.ReconnectDelay = 50;
request.KeepAlive = true;
request.UserAgent = useragent;
request.AllowAutoRedirect = true;
request.IgnoreProtocolErrors = true;
request.EnableEncodingContent = true;
request.MaximumAutomaticRedirections = 5;
request["Upgrade-Insecure-Requests"] = "1";
request["Accept-Language"] = "ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7";
request["Accept"] = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3";
bool status = request.Get(url).IsOK;
if (status)
{
project.SendInfoToLog("", "Status -> " + status + " -> Count -> " + p.Count.ToString(), true);
sb.Append(p.Count.ToString() + "|");
}
}
catch (HttpException e)
{
string answer = string.Empty;
switch (e.Status)
{
case HttpExceptionStatus.Other:
answer = "Неизвестная ошибка";
break;
case HttpExceptionStatus.ProtocolError:
answer = "Код состояния: " + (int)e.HttpStatusCode;
break;
case HttpExceptionStatus.ConnectFailure:
answer = "Не удалось соединиться с HTTP-сервером";
break;
case HttpExceptionStatus.SendFailure:
answer = "Не удалось отправить запрос HTTP-серверу";
break;
case HttpExceptionStatus.ReceiveFailure:
answer = "Не удалось загрузить ответ от HTTP-сервера";
break;
}
project.SendErrorToLog("", answer, true);
}
}
});
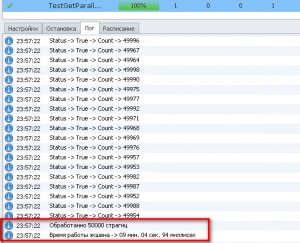
project.SendInfoToLog("", "Обработанно " + count2 + " страгиц", true);
var list = sb.ToString().Split(new string[]{ "|" }, StringSplitOptions.RemoveEmptyEntries);
FileSystem.FileAppendString(project.Directory + "\\Result.txt", string.Join("\r\n", list), true);
}
Шива
Client
- Регистрация
- 05.02.2018
- Сообщения
- 1 084
- Благодарностей
- 339
- Баллы
- 83
Например что бы спарсить зеннолаб не нужно парсить все перебором а можно взять карту сайта
https://zennolab.com/discussion/sitemap.php
Выдернуть все урлы c threads и получить id всех топиков
https://zennolab.com/discussion/sitemap.php
Выдернуть все урлы c threads и получить id всех топиков